Vision
The reusable components represent “mini” products that are at the core of our strategy for different “data-driven” services in different domains. At high level, such services concern data collection, integration, management, search, analytics and sharing, and are designed and developed in a generic manner to address as many industrial stakeholders’ needs as possible. The different components are designed based on principles like flexibility, reusability, extensibility, separation of concerns, and interoperability. All reusable components are built based on state-of-the-art open source technologies but are released as closed source components.
RC#1: S5-Collect
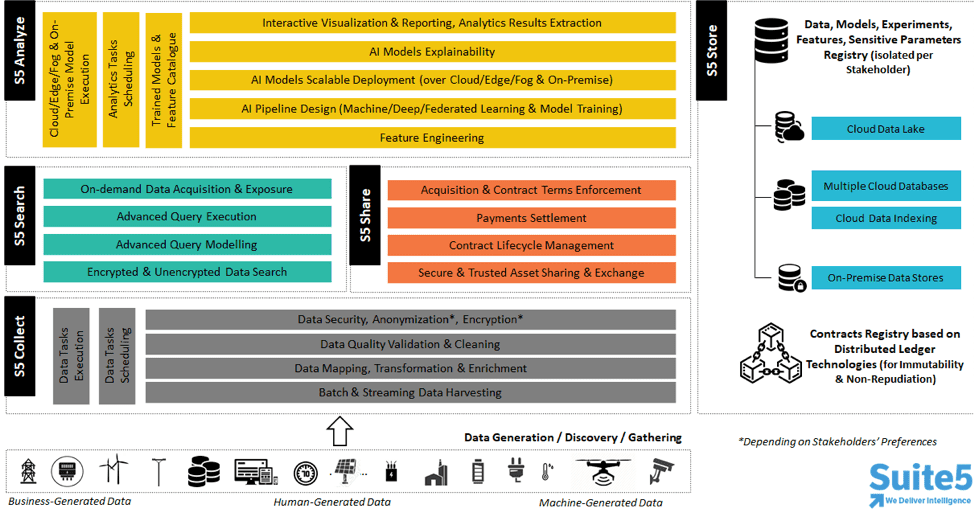
Reusable Component #1 (RC#1): S5-Collect (or Data Collection) is responsible for collecting and managing data from any data source for any domain. It practically handles how data are collected, e.g. once, based on a specific schedule or at real-time, through different mechanisms: (i) as batch data files (in csv/tsv, json, xml, other formats), (ii) via APIs exposed by external, 3rd party systems, (iii) via APIs exposed by RC#1 in order for stakeholders to push data, (iv) via streaming data mechanisms. In order for the data to be stored in an homogenous and consistent manner, it also allows the data providers (who are either IT users or developers who know their data) to configure different pre-processing steps: (a) Data Mapping to harmonize the data and gain a common understanding, while ensuring their semantic consistency and enrichment, based on different data models per domain, (b) Data Cleaning to increase the data quality by handling any potential duplicates, outliers or missing values, (c) Data Anonymisation to avoid any disclosure of personal data, (d) Data Encryption to further safeguard the data (note: future feature), (e) Data Loader that handles the permanent storage of the data. Once the data check-in job configuration is finalized, the respective data asset is created and the data provider needs to define a set of metadata (that essentially provide the data asset “profiling”) and the applicable access policies (to restrict/allow access to the dataset based on different attributes of the organization/user).
It needs to be noted that there is a complete separation of the “design” time during which the data provider configures how a data check-in job will be executed, from the “execution” time during which the data check-in job is actually executed according to the schedule set. The configuration of the data check-in job always happens in the cloud platform while the execution of the data check-in job may occur in the cloud or on-premise (in an environment that is intended to be installed in a server or a gateway). To this end, RC#1 works on different modes: (i) cloud mode, according to which the data check-in jobs configuration and execution happens in the cloud, (ii) cloud-on-prem mode (note: future feature), according to which the data check-in jobs configuration happens in the cloud and the execution in the on-premise environments. It needs to be noted that the outcomes of each data check-in step are stored in a temporary object storage to ensure full traceability of the process while the credentials of the different services (e.g. 3rd-party APIs) are securely stored.
RC#2: S5-Search
Reusable Component #2 (RC#2): S5-Search (or Data Search) is responsible for search and retrieval of data on demand. To this end, it handles the indexing of the assets’ metadata that have been provided by the data provider, or have been extracted or calculated from the data before the data storage. In order to allow any data consumer to find the data they are really interested in, it allows them to perform faceted search over the data assets they are eligible to access (as the access policies defined by the respective data providers are resolved before the data consumers view any results). The data consumer is able to filter the results or search for specific values in certain metadata or for specific fields from the data model that should appear in the data. A more advanced version of a query builder to define and execute queries over the actual data (either they are stored in an encrypted or unencrypted form) is part of a future release.
In essence, RC#2 provides access to the data that have been stored in RC#1. Through RC#2, the data consumers are able to retrieve an overall dataset or a data slice of their choice (containing only the fields/columns they need) based on the query parameters they set (as a filter). Each query is stored with a unique UUID and, depending on the respective data collection method, the data contained in its associated data asset(s) can be retrieved at any moment by any authorized 3rd party application through (a) the RCs APIs or (b) the streaming mechanism the data became available (without having been processed by RC#1 though), as well as (c) as a downloadable file in the case of Other files.
RC#3: S5-Analyze
Reusable Component #3 (RC#3): S5-Analyze (or Data Analytics) is responsible for unveiling actionable insights on the data (that are owned or have been acquired by a data provider). It is intended for use by different data consumers: (a) data scientists who prepare the analytics pipelines, (b) business users who can view the analytics results and gain insights into their operations, and (c) 3rd-party developers who want to retrieve the analytics results and display them in their applications. It practically allows a data consumer to design and configure an analytics pipeline containing different, multiple blocks for: (i) any data preparation functions that are needed to manipulate, filter, integrate, synchronize and perform computations over the data in order to become appropriate for running an analysis; (ii) any machine learning or deep learning algorithms that are already configured, trained and available in RC#3 (note: the inclusion of code by the data scientists in RC#3 is part of a future feature, while the algorithms are classified into: i. basic that are provided as-is in an out-of-the box manner from different libraries; and ii. baseline/pre-trained that have been already trained with specific datasets to provide a specific business-oriented outcome). The expected input of each block and the whole pipeline is explicitly defined and may range from batch data stored in the RCs to near real-time data directly sent to trigger the analytics execution. The desired output of the pipeline can be provided in different ways: (a) as a fully configurable visualization that can be saved by the user, (b) as raw data that can be retrieved from a 3rd-party application through the RCs APIs or can be exported as a file, and (c) as part of a broader report (note: future functionality). The execution of an analytics pipeline can occur in different modalities: (a) in the cloud, (b) in dedicated secure spaces per organization (for increased security), (c) on-premise (in an environment that is intended to be installed in a server or a gateway), while it can be triggered in multiple ways: (i) once, (ii) according to schedule, (iii) on demand from the RC#3 APIs through an external 3rd-party application, (iv) when certain circumstances occur (e.g. an outlier is detected in the data stored in RC#1). It is thus evident that RC#3 aims to achieve separation of concerns between the data preparation, the pipeline design, the algorithms training and the pipeline execution, to the extent it is possible.
The configuration of an analytics pipeline always happens in the cloud platform while the execution of the analytics pipeline may occur in the cloud (esp. in secure spaces) or on-premise (in an environment that is intended to be installed in a server or a gateway) and involves fetching the necessary input data (that may be stored in an encrypted or unencrypted form or become available through an API). The preparation, experimentation and training of the different supported algorithms currently occurs “offline” by our data scientists and the algorithms are already packaged and checked in in RC#3 along with their appropriate description, necessary inputs, expected output and available configuration. To this end, RC#3 works on different modes: (i) cloud mode, according to which the analytics pipeline configuration and execution happens in the cloud, (ii) cloud-secure-spaces mode, according to which the analytics pipeline configuration happens in the cloud, but the execution occurs in secure spaces in the cloud that are dedicated to each user/organization for increased security and where the data need to be effectively transferred and stored, (iii) cloud-on-prem mode, according to which the analytics pipeline configuration happens in the cloud and its execution in the on-premise environments. Depending on the analytics pipeline configuration, it is anticipated that the users will be prevented from executing resources-intensive algorithms in the on-premise environment, esp. in its gateway version.
Note: the functionalities that are further targeted to the data scientists needs, as well as AI explanability aspects, are planned for a future release.
RC#4: S5-Share
Reusable Component #4 (RC#4): S5-Share (or Data Sharing) is responsible for sharing and exchanging data assets in a trustful and legitimate manner. It allows data asset providers and data asset consumers to proceed to bilateral or multi-party contracts that dictate the terms of any data asset exchange among them. The term data asset practically embraces (single or multiple) datasets, basic algorithms, baseline algorithms, analytics results, visualizations and reports that belong to different parties (considering potential derivation aspects) and can be shared with different stakeholders. RC#4 essentially allows for managing the lifecycle of smart contracts, including their drafting, negotiation, signature, payment, activation and cancellation, while ensuring the contract immutability and non-repudiation through Distributed Ledger Technologies. Online payments through crypto currencies, as well as the renumeration of the involved parties in a contract, also fall within the scope of RC#4. All RCs need to enforce each contract’s terms, e.g. if downloading locally a dataset is not allowed, when a contract expires, etc.
Cross-cutting RCs
RCs Cross-cutting Aspects: The underlying storage is provided through S5-Store that anticipates: (a) cloud object storage (for temporary storage purposes), (b) multiple cloud databases (e.g. a NoSQL database for data storage, a relational database for transactional data, a secure vault for sensitive parameters), (c) an indexing engine for the metadata (and in the future the data), (d) on-premise data stores (in case the data are not to leave an organization’s premises), (e) data asset contracts’ ledger and (f) registries of data models, algorithms, experiments and features. The data models that underpin the overall RCs operation and provide the actual domain expertise are managed in the Data Model Manager that allows us (as model administrators) to create, publish and maintain the different data models based on a concrete set of evolution and consistency rules that are enforced to ensure that new data needs and requirements are embraced without creating problems on the already stored data. The RCs are complemented by a real-time notification mechanism to instantly inform the platform users about the progress and outcome of any ongoing jobs in the platform. Finally, from a user management perspective, the RCs anticipate either individual user access or organization-based access (that allows multiple users of the same organization to have access to the same data asset, for example).
RCs Overall Perspective
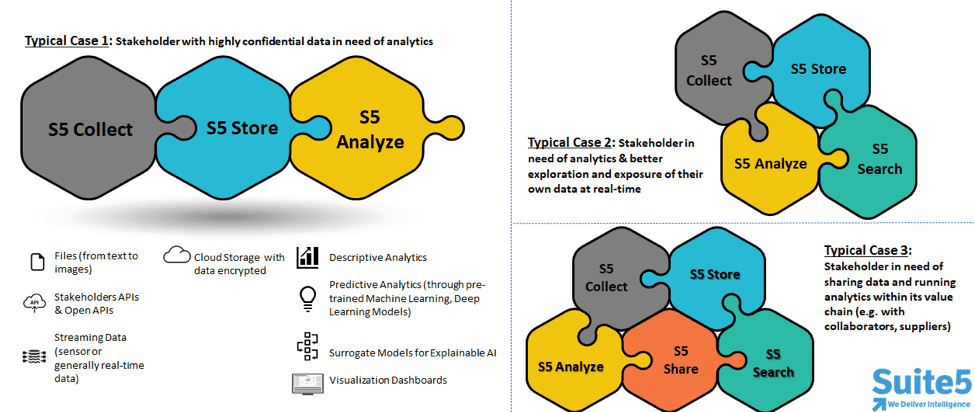
The high-level view of the intended functionalities of all RCs is provided below.
The technology offering we provide collectively builds on RC#1-4, but allows for customized end-to-end data solutions (typically provided as a service) that are adaptable to different stakeholders’ needs, as depicted in the following figure.