Analysis Overview
The rc-analysis-execution library provides methods for performing data ingestion, processing, analysis and export, as part of a data processing workflow (the term pipeline is also commonly used). The term pipeline (/workflow) in this context refers to a sequence of steps that have been defined in a configuration file written in a specific predefined format that the library can parse (see below for details).
Workflow Configuration
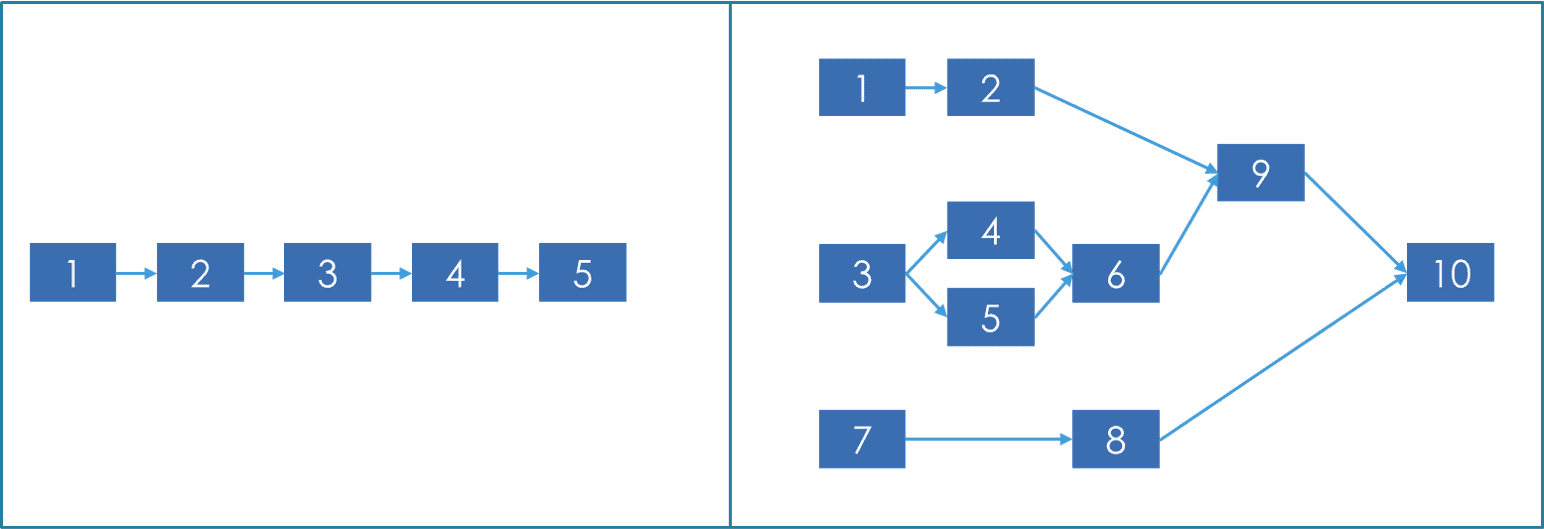
The library supports the execution of steps defined as a directed acyclic graph (DAG), i.e. both single-line pipelines, but also graph-like pipelines, as the ones shown in the image below:
The pipeline configuration file includes the following information:
{
"executionId": "String: The execution id, which is used mainly to keep track of the logs generated throughout the execution & to facilitate interaction with the frontend/backend that sent the specific pipeline configuration file for execution",
"name": "String: The name given to the execution (not used by the library except for logging purposes if needed)",
"configuration": {
"execution": "String: The type of the execution, which is one of (normal, test, dry) - see 'Execution Modes' section below",
"output": "String: Defines the target task id in the case of test or dry execution mode and is explained in the 'Execution Modes' section below"
},
"tasks": "List of objects: A list of the tasks included in the pipeline. The task configuration is further described ***here***"
}Currently the library supports the following 2 execution "frameworks":
- Spark - In this mode all pipeline steps are executed over Spark using the Pyspark library. For more information see the corresponding section (more info will be added about the libraries used)
- Python - - In this mode all steps are executed as simple python scripts. For more information see the corresponding section (more info will be added about the libraries used)
The framework that should be used to execute the steps defined in the configuration file is not specified in the pipeline configuration above. Instead, the library offers two flavours (one for each execution framework) and the right flavour (i.e. the corresponding pipeline execution function) should be invoked.
The library offers a consistent API (to the extent possible) in the sense that the same configuration file can be executed in both frameworks. Exceptions apply when it is not possible to offer the exact same functionality through Python and Spark. Such cases will be documented in the repository documentation.
Execution Modes
The service supports 3 modes of execution, and each mode produces a different output.
- When normal execution is selected, the service will execute all the defined tasks. If one or more data export tasks are defined, the service will export the processed dataframe in the selected location/s.
- For the dry execution mode, the service needs a target task. The service will return the structure/schema (i.e. column names and types) of the dataframe that is generated by the selected target task (i.e. the output dataframe of the task).
- For the test execution mode, the service again needs a target task. The service will return the structure/schema (i.e. column names and types) and a small sample of the dataframe that is generated by the selected target task (i.e. the output dataframe of the task)
When the execution framework of the pipeline is Spark, the dry and test run modes will not cause all tasks to be fully executed.
Task Types
Each task in the pipeline defines a specific data processing function from the following four categories:
- Data import: Functions enabling ingestion of data from various sources, e.g. files, APIs, RC#2 database etc. Data import functions always provide a dataframe as output (pyspark/pandas dataframe depending on the execution framework). Note: The current version of the library offers limited data import functionalities, more information for which can be found in import docs.
- Data manipulation: Functions enabling various processing functionalities on dataframes, e.g. transformations, filters, merges, etc. A detailed list of the available data manipulation functions can be found in manipulation docs.
- Data analysis (model-related tasks): Functions offering the core data analysis functionalities, including ML/DL model training, evaluation and application, as well as functions for ML/DL feature engineering. Note: The current version of the library offers limited data analysis functionalities, more information for which can be found in in model docs.
- Data export: Functions enabling exporting dataframes to various forms, e.g. files, APIs, visualisations, etc. Note: The current version of the library offers limited data export functionalities, more information for which can be found in in export docs.
High-level Flow
The following diagram presents a high-level view of the way the library handles a request to execute a pipeline, starting from the receival of a pipeline configuration file until the execution is completed, either successfully, or with an error.
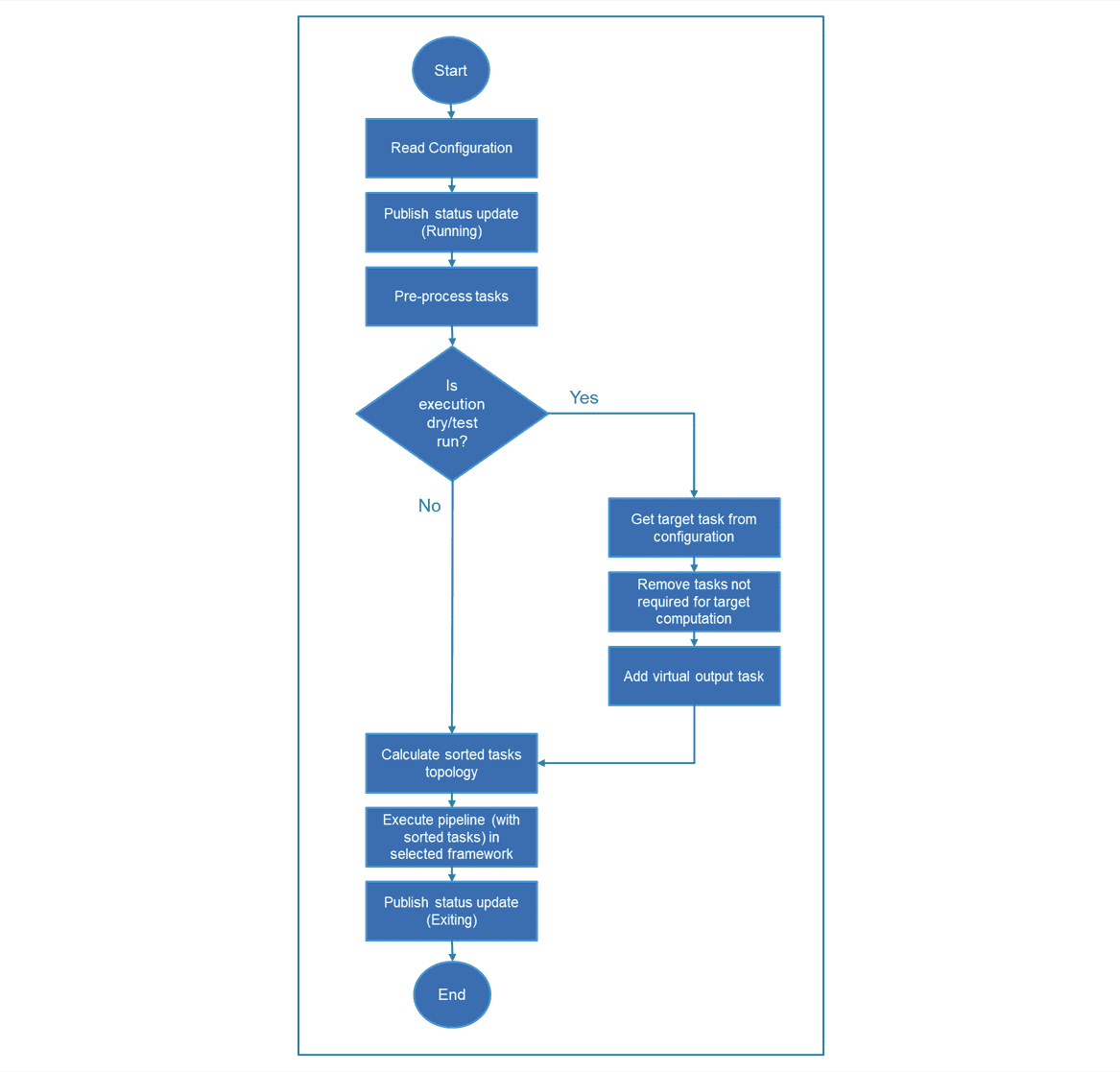
The processes shown in the flow diagram above are briefly explained below:
- Read configuration: The service parses the received json file with the pipeline configuration. In case of malformed file, an appropriate error message is logged and the process stops.
- Publish status update: The service has 3 message queues used to communicate status updates (e.g. the ones shown in the diagram to denote that the process started/finished), outputs (e.g. the structure of the target task for which a dry run was requested) and various logs depending on the task execution process.
- Pre-process tasks: Required pre-processing steps of the tasks given in the pipeline configuration (mainly related to the topological sorting step)
- Remove tasks not required for target computation: When a dry/test execution is requiested for a specific task in the pipeline, not all tasks of the pipeline need to be considered. As an example, to perform a dry run execution for task 6 in the graph image above, only tasks 3,4,5 need to be considered. All other tasks are removed before starting the execution, as computing them will only slow down the process.
- Add virtual output task: In case of dry/test run, an additional task is added right after the defined target task. This task is not part of the initial configuration and it is a wrapper for a helper function that is responsible for returning the structure of the task (and the sample, in case of a test run).
- Calculate sorted tasks topology: Topological sorting of the tasks in the pipeline configuration. The Python library toposort is used to perform this operation.
- Execute pipeline: This is a set of processes that handles the actual execution of the sorted tasks using the specified execution framework. More information can be found in the respective documentation pages.
Workflow Example
The image below presents a pipeline with 6 tasks: 1 data import task, 3 data manipulation tasks, 1 data analysis task and 1 data export task.
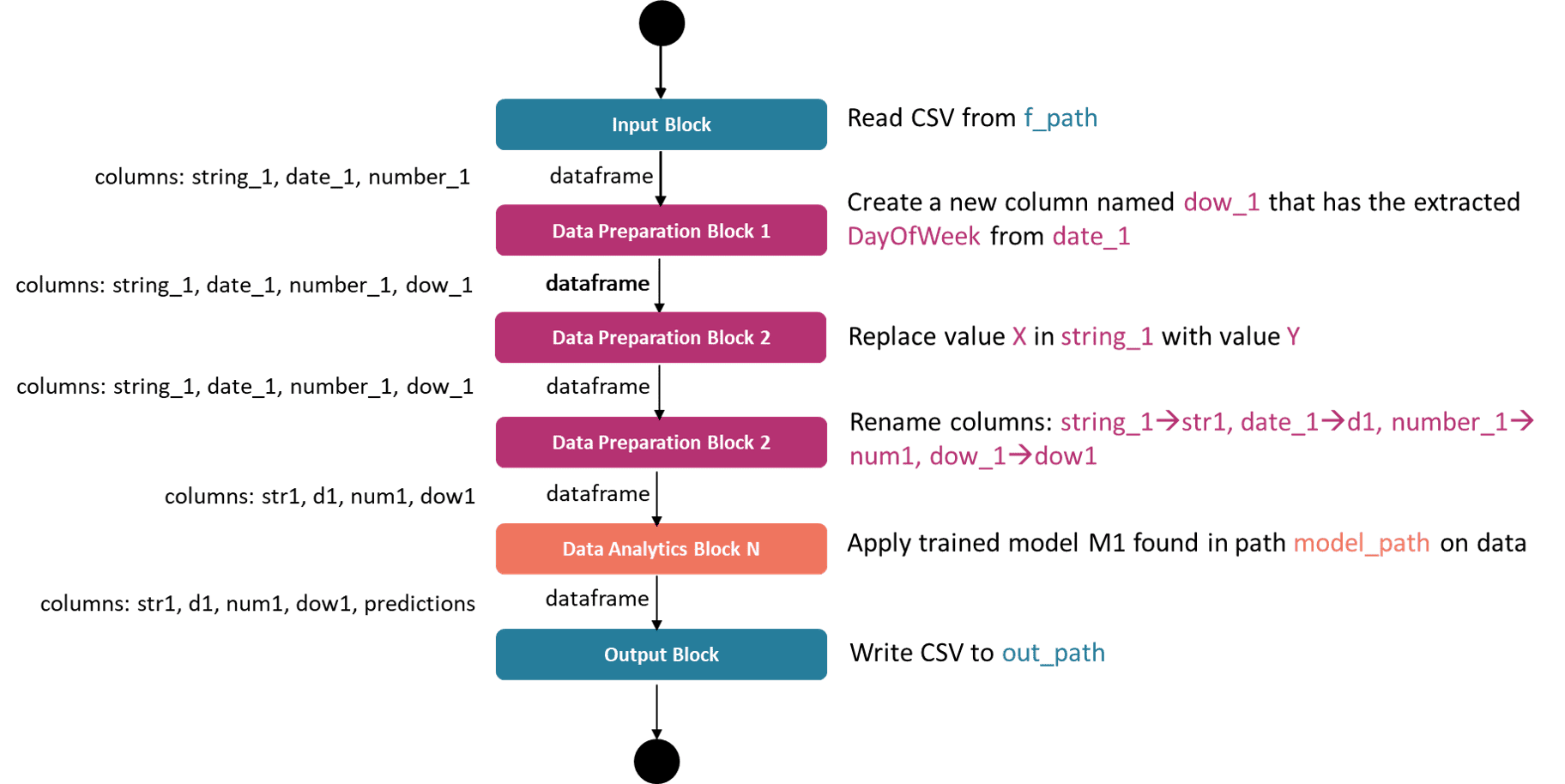
The coloured parts of the text on the right side of the task blocks denote the parameters of these tasks, i.e. the required user configuration in order for the task to have all information needed to be executed. The dataframe columns on the left of the task blocks are shown to highlight that the column names (and types) of the output dataframe of a specific task often need to be known when configuring the next task. As an example, the "Data Preparation Block 1" needs to know that the output dataframe of "Input Block" has a column named "date_1" that id of type date/datetime in order to properly extract the day of week information.