Analysis Overview - Product
The product-analytics-execution library provides methods for performing data ingestion, processing, analysis and export, as part of a data processing workflow (the term pipeline is also commonly used). The term pipeline (/workflow) in this context refers to a sequence of steps that have been defined in a configuration file written in a specific predefined format that the library can parse (see below for details).
Workflow Configuration
The library supports the execution of steps defined as a directed acyclic graph (DAG), i.e. both single-line pipelines, but also graph-like pipelines, as the ones shown in the image below:
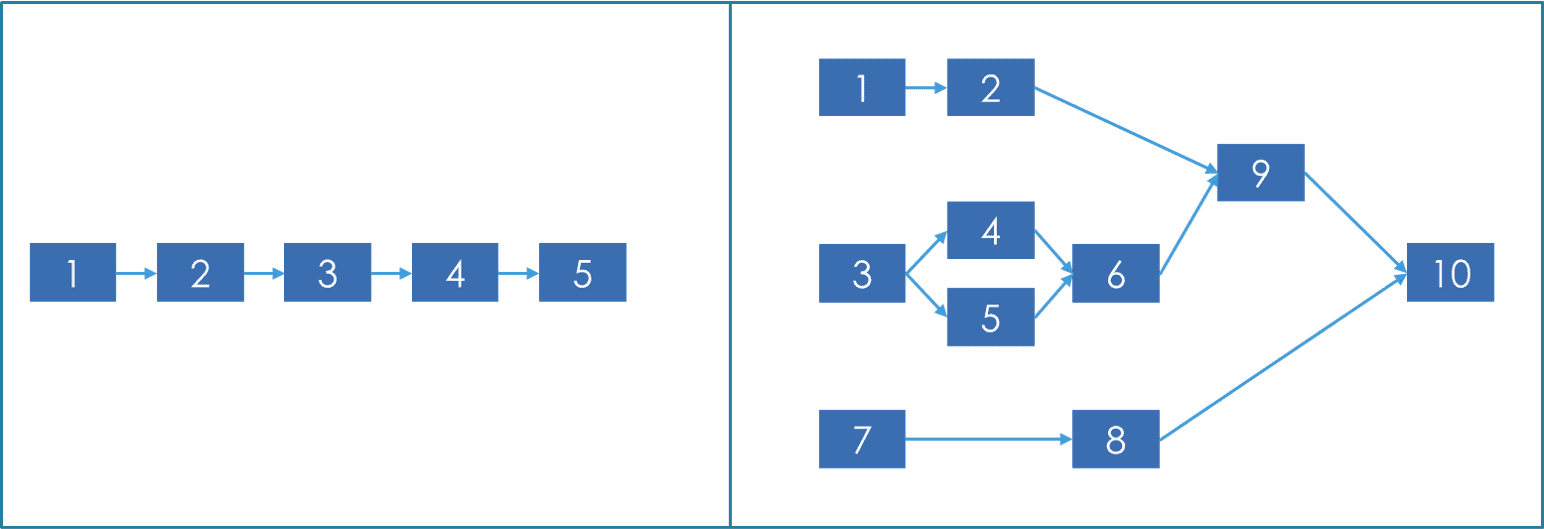
The pipeline configuration file includes the following information:
{
"id": "String: The workflow id (corresponds to the one in the BE database)",
"executionId": "String: The id of the execution (corresponds to the one in the BE database)",
"configuration": {
"sample": "Dict: Provides information about the data subset that should be used in a test run - more info below",
"pipelines": "List[String]: Not used in current version",
"version": "String: version of the analytics library to be used to execute the configuration - This is used by BE, not execution library.",
"framework": "String: the execution framework to be used: python3 or spark3 - more info below",
"frameworkVersion": "String: version of the framework (python or spark)",
"execution": "String: type of execution to be performed (normal, test, dry) - more info below",
"output": "String: target task of test/dry run, null/ignored in normal runs",
"userId": "Will be used in future version for monitoring purposes",
"organisationId": "Will be used in future version for monitoring purposes",
"nextSchedule": "Will be used in future version for monitoring purposes"
},
"tasks": "List[Dict]: A list of the tasks included in the pipeline. The task configuration is further described ***here***",
"vault": "Dict: Information coming from Vault (Mongo credentials)"
}Supported Frameworks
Currently the library supports the following 2 execution "frameworks":
- Spark - In this mode all pipeline steps are executed over Spark using the Pyspark library.
- Python - - In this mode all steps are executed as simple python scripts.
Many functionalities are available in both frameworks through the same blocks and to the extent possible an effort has been made to offer a consistent API in the sense that the same configuration file can be executed in both frameworks and produce the same results. Exceptions apply when it is not possible to offer the exact same functionality through Python and Spark. Such cases are usually on purpose handled in a different way because of the frameworks' inherent differences (e.g. related to the way nulls are handled or caused by spark's lazy evaluation etc.) and are documented per block in the repository documentation. The aforementioned common blocks belong to the import, preparation and export functionalities (more info on these categories in the "Task Types" subsection below), i.e. not the Machine Learning blocks which are specific to the underlying framework because different ML libraries are available for usage.
Execution Modes
The service supports 3 modes of execution, each serving a different purpose and providing different outputs.
- When normal execution is selected, the service will execute all the defined tasks. If one or more data export tasks are defined, the service will export the processed dataframe in the selected location/s.
- For the dry execution mode, the service needs a target task. The service will return the structure/schema (i.e. column names and types) of the dataframe that is generated by the selected target task (i.e. the output dataframe of the task). Dry runs cannot be performed on export blocks and on ML train blocks, since no dataframe is returned by them.
- For the test execution mode, the service again needs a target task. The service will return the structure/schema (i.e. column names and types) and a small sample of the dataframe that is generated by the selected target task (i.e. the output dataframe of the task). As with dry runs, test runs cannot be performed on export tasks for the same reason. However, test runs on ML train blocks are possible and they are equivalent to performing a normal run of the subset of tasks that are required in order for the train task to be performed (i.e. only the train block and its upstream tasks are executed).
Important note: Although the main purpose of dry/test run modes is to get the structure/sample of the target task output, in Python the structure/sample of ALL upstream tasks of the target task will be also returned one by one as the execution progresses. This is a core difference compared to Spark, since there we do not want to force the dataframe to be evaluated on each step as this would cause significant performance issues (and would cancel the benefits of having Spark).
Sampling options
The example configuration shown above includes a sample property of type Dict. An example of the information in this dictionary is as follows:
"sample": {
"size": {
"rowsCount": 1000,
"percentage": null
},
"selection": "first"
},The values in the sample field are only considered by the execution library in test runs to define the subset of the input data that should be used in order to provide the requested data samples. An exception to this is the s5.ReadMultipleParquet block which does not apply any type of sampling, because of the agreement that the BE will send an appropriate sample parquet file as input. For other input blocks, the sample information is used to define whether the sample will be retrieved from the start/end of the input data or randomly and whether an exact number of rows or a percentage of the total rows/records should be returned. In particular:
- rowsCount: Integer: The number of rows to be returned in the result df
- percentage: Float(0-1): The percentage of rows to be returned in the results df - if both rowsCount and percentage are provided, percentage is ignored.
- selection: String(first, last, random): How to select the sample, i.e. from the start/end of the input or randomly (i.e. non consecutive records randomly selected from the input data).
More information on how these options are used depending on the execution mode and the selected tasks for execution can be found in the project repo documentation.
Task Types
Each task in the pipeline defines a specific data processing function from the following four categories:
- Data import: Functions enabling ingestion of data from various sources, e.g. files, APIs, MongoDB etc. Data import functions always provide a dataframe as output (pyspark/pandas dataframe depending on the execution framework). More information can be found in import docs.
- Data manipulation: Functions enabling various processing functionalities on dataframes, e.g. transformations, filters, merges, etc. A detailed list of the available data manipulation functions can be found in manipulation docs and in nested manipulation docs.
- Machine Learning: Functions offering the core data analysis functionalities, including ML/DL model training, evaluation and application, as well as functions for ML/DL feature engineering. More information on these blocks can be found in model docs.
- Data export: Functions enabling exporting dataframes to various forms, e.g. files (csv, parquet, json) and MongoDB collections. More information can be found in export docs.
Simple Workflow Example
The image below presents a pipeline with 6 tasks: 1 data import task, 3 data manipulation tasks, 1 data analysis task and 1 data export task.
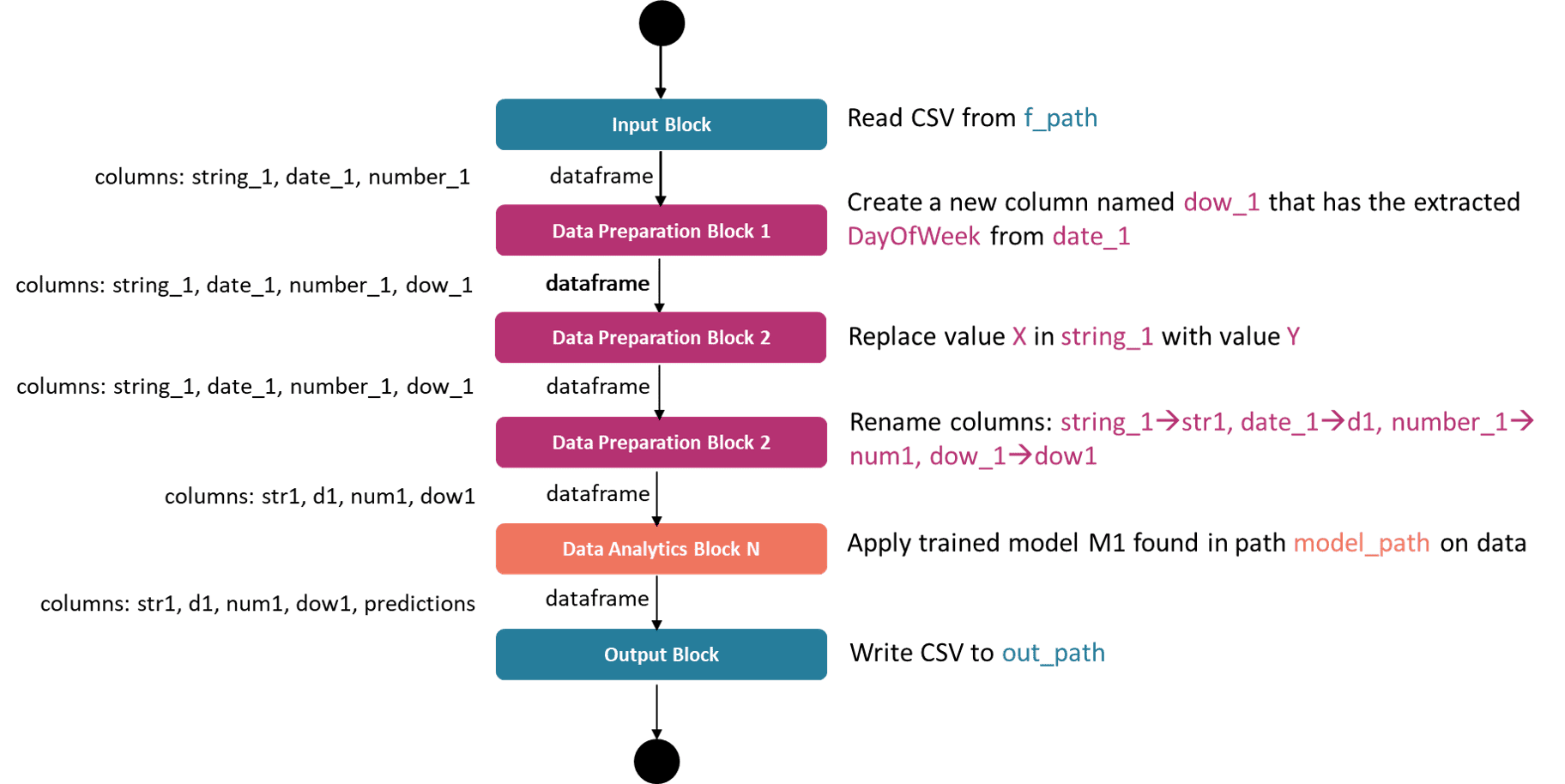
The coloured parts of the text on the right side of the task blocks denote the parameters of these tasks, i.e. the required user configuration in order for the task to have all information needed to be executed. The dataframe columns on the left of the task blocks are shown to highlight that the column names (and types) of the output dataframe of a specific task often need to be known when configuring the next task. As an example, the "Data Preparation Block 1" needs to know that the output dataframe of "Input Block" has a column named "date_1" that id of type date/datetime in order to properly extract the day of week information.
High-level Flow
The following diagram presents a high-level view of the way the library handles a request to execute a pipeline, starting from the receival of a pipeline configuration file until the execution is completed, either successfully, or with an error.

The processes shown in the flow diagram above are briefly explained below:
- Read (Parse) Configuration: The service parses the received json file with the pipeline configuration. In case of malformed file, an appropriate error message is logged and the process stops. Note: This initial parsing does not perform a full validation of the configuration file. Various properties are checked in different stages after the initial parsing depending on the overall configuration and the execution flow (i.e. when/if they are needed). When a required property is identified as missing, an error message will be returned.
- Publish status update: The service has 3 message queues used to communicate status updates (e.g. the ones shown in the diagram to denote that the process started/finished), outputs (e.g. the structure of the target task for which a dry run was requested) and various logs depending on the task execution process.
- Validate configuration options: Ensure that the type of execution requested is inline with the overall configuration. At this stage this step only performs the following checks (but can be extended): That a dry/test run is not attempted on an export block, that a dry run is not attempted on an ML train block and that a target output task had been defined in case of a test/dry run.
- Calculate sorted tasks topology: Topological sorting of the tasks in the pipeline configuration. The Python library toposort is used to perform this operation. In case of a test/dry run, in this step the subset of tasks that are required in order to return the requested structure/sample information is also calculated. The output of this step in this case will be the topologically sorted subset of tasks (i.e. the target task and all its upstream tasks).As an example, to perform a dry run execution for task 6 in the graph image above, only tasks 3,4,5 need to be considered. All other tasks are removed before starting the execution, as computing them will only slow down the process.
- Add virtual output task (SPARK): In case of dry/test run, an additional task is added right after the defined target task. This task is not part of the initial configuration and it is a wrapper for a helper function that is responsible for returning the structure of the task (and the sample, in case of a test run). This is only done in Spark since in Python all intermediate tasks will also publish their structure/sample, since the tasks are fully executed and thus these results are available.
- Define tasks' configuration settings: Define some execution-level properties that should be passed to the tasks and control their behaviour. Such properties include the sampling information previously described, whether a task should report on its structure/sample, etc.
- Execute pipeline: This is a set of processes that handles the actual execution of the sorted tasks using the specified execution framework. Tasks are executed one by one in the order defined by the topological sorting, each one performing its operation, reporting on its outcomes as instructed and passing its result to subsequent tasks.
- Report on processed files/MongoDB docs: In case of a normal execution, an update is sent to the results' queue containing information about the following: parquet files that were create through export blocks (not all blocks offer this), parquet files that were deleted as a result of an export operation with "replace" mode (the common path of these files' folder and not the individual paths are returned), the parquet files that were successfully read through import blocks (again not all blocks offer this), the id of the last record read from each MongoDB collection that was accessed through an import block (again, only selected blocks offer this). This report is used by the BE in different processes (e.g. to update the files' table, to update the info used for reading only new data etc.)
Supported libraries
The libraries supported in the current version (v0.5+) of the execution library are as follows:
| Library | Current Version | Previous Versions |
|---|---|---|
| pandas | 1.5.0 | 1.2.2 |
| scikit-learn | 1.1.2 | 0.24.1 |
| statsmodels | 0.13.2 | 0.12.1 |
| pmdarima | 2.0.1 | 1.8.3 |
| XGBoost | 1.6.2 | 1.5.0 |
| tensorflow (keras) | 2.10.0 | 2.4.1 |
| pyspark (MLlib) | 3.3.0 | 3.0.2 |
Notes:
- The library versions shown in the "Current Version" column are the ones that should be used when trained models are registered in the Platform
-
Models trained inside the platform using the previous versions of the libraries can still be used, with the following exceptions:
- KNN models from scikit-learn v0.24.1 cannot be used & need to be retrained
- MLlib models from v3.0.2 cannot be used & need to be retrained
- Models trained externally using previous supported versions that have been already successfully uploaded (registered) before switching to the current versions can still be used, with the same exceptions (scikit-learn KNN & MLlib) mentioned in point 2 above.
- In some cases under points 2 and 3 certain attributes are missing from the old models which are required in the current library versions. In these cases these attributes are added during the model application phase, but without changing anything in the stored model.