Harvester
Introduction
The Harvester service is responsible for retrieving data from various sources (files, external APIs, own APIs, Apache Kafka), converting data to json files (occasionally) and storing them in MinIO. In order to run, it needs a json configuration file as an input. As an output, it produces and stores files in MinIO and communicates the execution state as feedback to the Backend service, through RabbitMQ. Harvester service is implemented in python.
Requirements
A list of services that need to be deployed (running), in order for the Harvester to be fully functional:
Functionality
File Handler
If the user has selected File as the source, the file handler will be executed. Supported file types are CSV, JSON, XML, Parquet or Other. The user can upload more than one files, although they should have the same file type. The file handler will retrieve the user uploaded files from MinIO (/upload path), check the file type, convert the files to JSON if needed, and store them back to MinIO (/harvest path).
Additionally, if the user has selected the Very Large File as the source, the file handler will be also executed with supported file types the CSV and the Parquet. The user has available a MinIO bucket per data checkin pipeline where he can upload more than one files. The execution will run in Spark because of the very large files and it will perform all tasks per file.
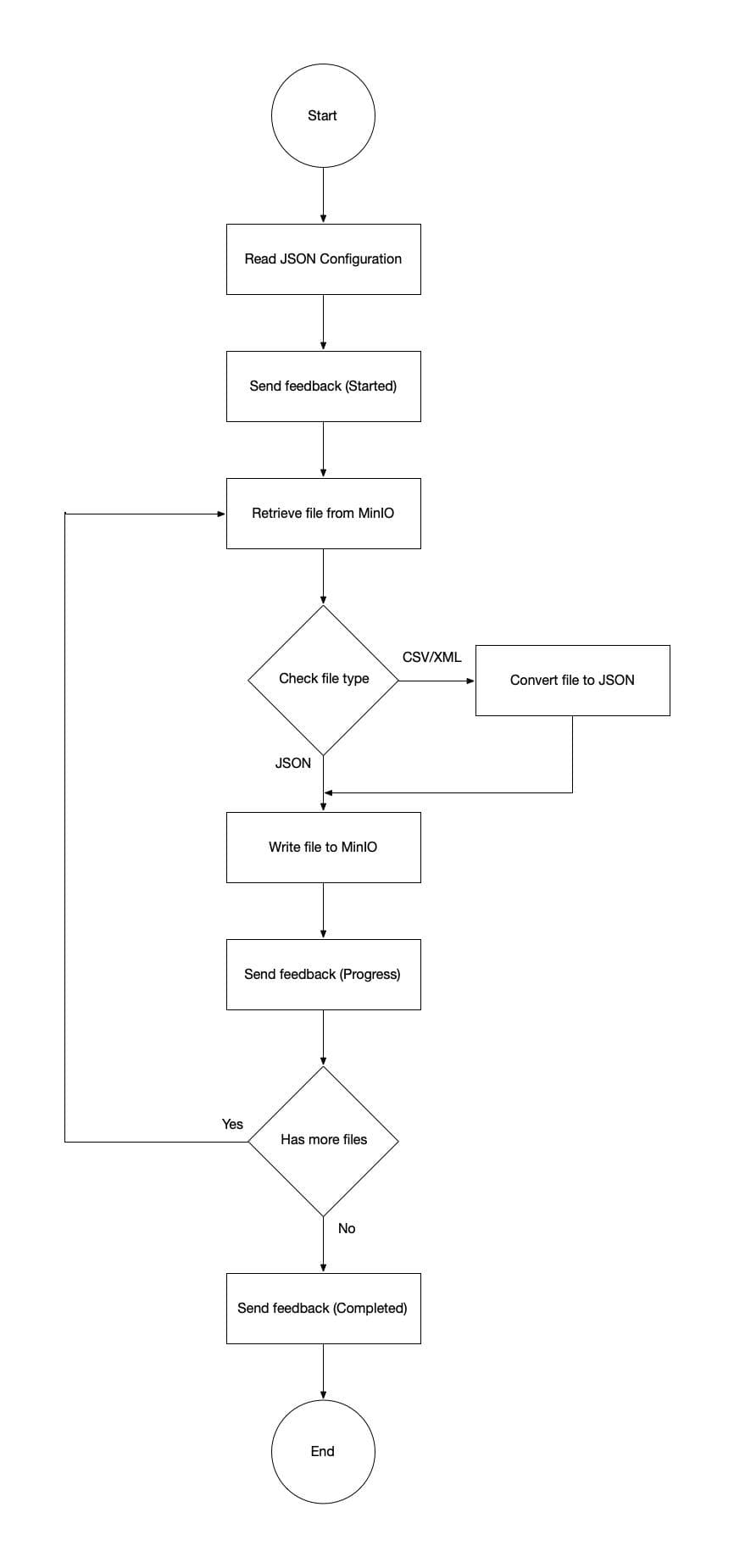
External API Handler
The External API Handler and the File Handler are the same. A json file is created from the external API which is retrieved by the Harvester. The flow is the same with File Handler.
API Handler
If the user has selected API as the source, the api handler will be executed. Two modes of operation are supported. The first is polling mode, in which the API is called multiple times, at 1 minute intervals, until the user defined end date is reached. For each API call, the response is parsed and we retain the fields that user has selected during harvester configuration in UI. The processed responses are stored to MinIO (/harvest path). In the second mode, the API is called once, the response is processed (as described in polling mode) and stored to MinIO (/harvest path). In case the user calls an API with pagination, the API Handler will gather all the responses together (until the max_requests number is reached or there are no more responses), process them and store them to MinIO.
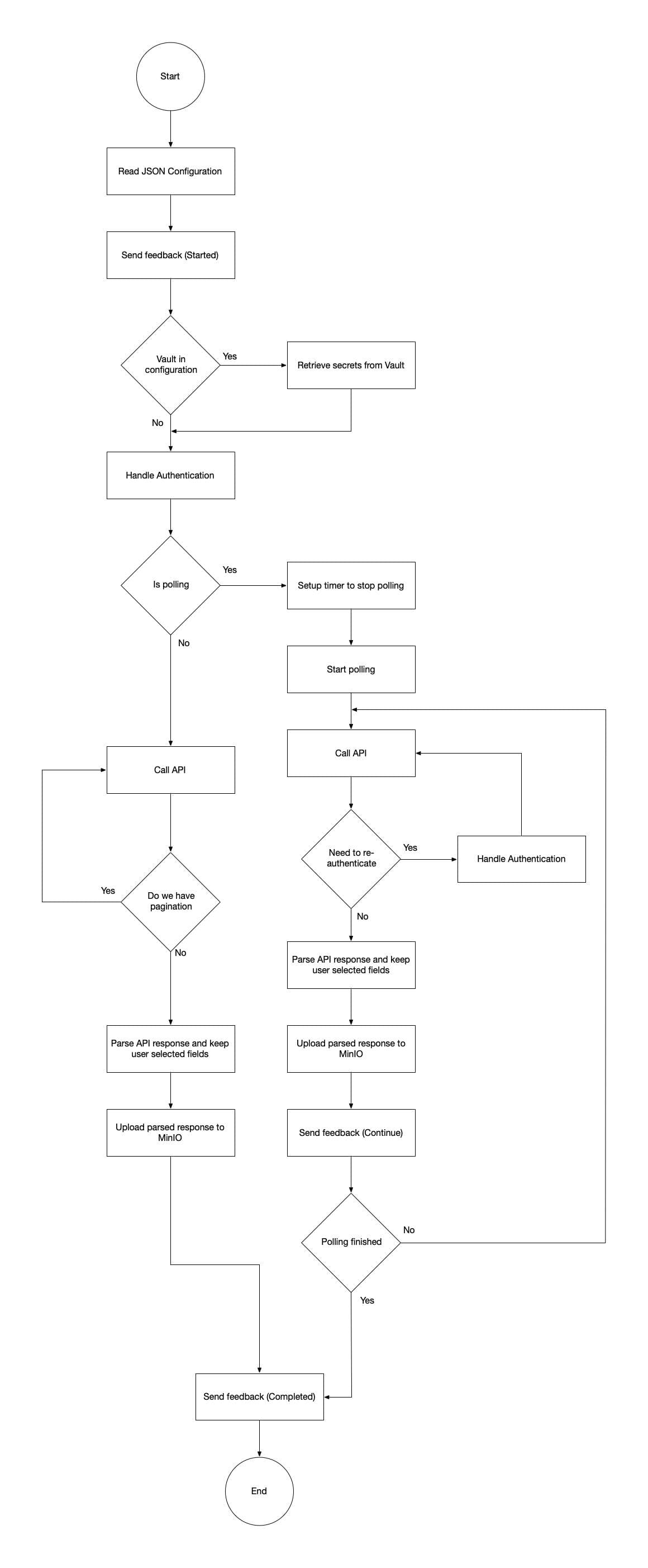
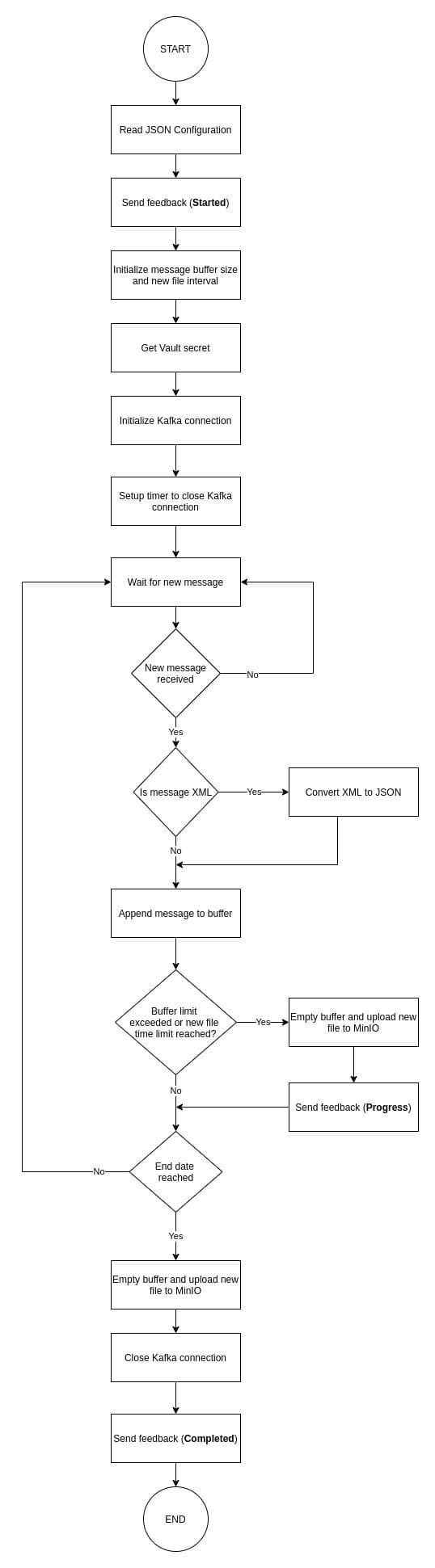
Kafka Handler
If the user has selected Kafka or ExternalKafka as the source, the kafka handler will be executed. Depending on the processing time a new file time limit will be set. If the processing time is 'hourly', the limit will be 10 minutes and if it is 'daily', the time limit will be 1 hour. The Kafka Consumer will stay connected to the Kafka Broker until the end date is reached. Each time a new message is received, it is appended in a local buffer. If the buffer size exceedes a predefined limit (1GB) or the new file time limit reached, a new file is created containing all the messages collected in the local buffer and it is uploaded to the MinIO (/harvester path). Supported message formats are JSON and XML. All XML messages are converted to JSON.
Configuration Files
A JSON configuration file is required from the Harvester. Depending on the user selected input source, the configurations files will differ. The requirements of the configuration file are described in the harvester_schema.py file that exists in the Harvester Service.