Transformer
Introduction
The Transformer service is responsible for merging the files that Harvester produced, applying the user defined transformations and storing the new file back to MinIO. In order to run, it needs a json configuration file as an input. As an output, it produces and stores the flattened transformed file in MinIO and communicates the execution state as feedback to the Backend service, through RabbitMQ. Transformer service is implemented in python.
Requirements
A list of services that need to be deployed (running), in order for the Transformer to be fully functional:
Functionality
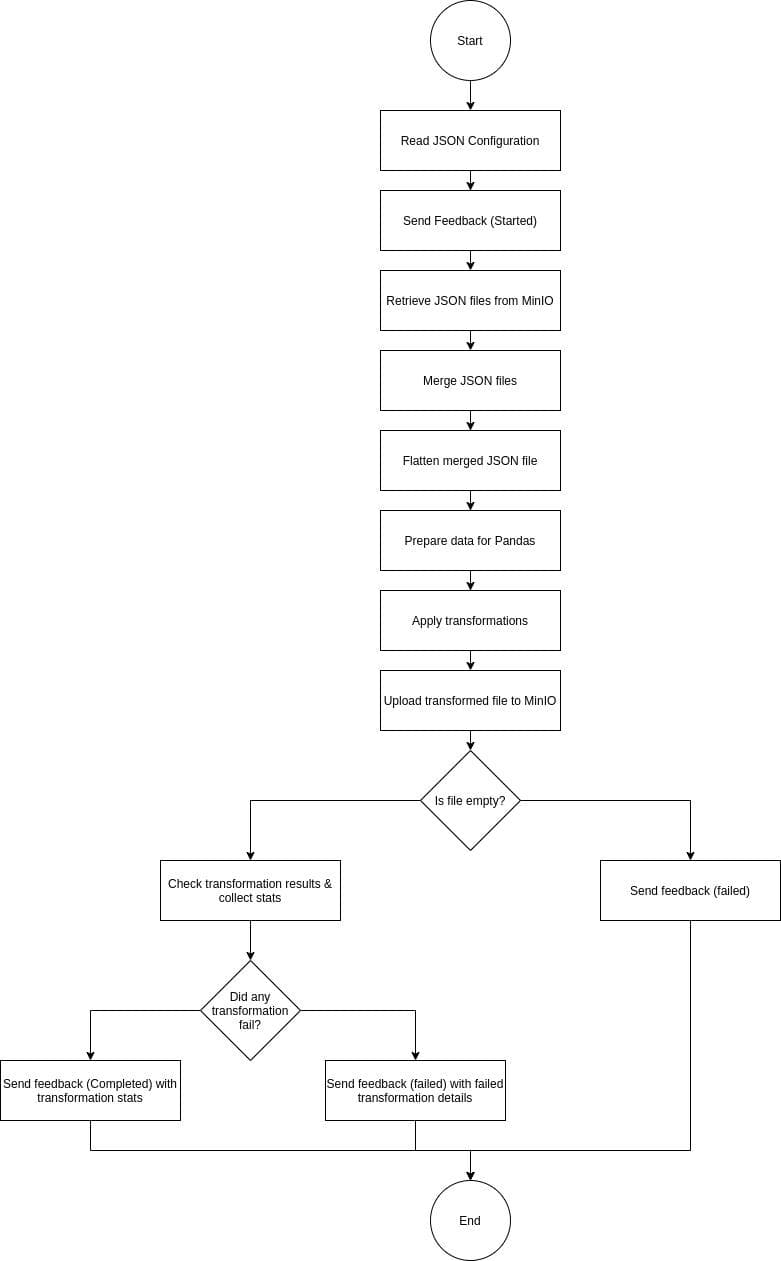
The functionality of the Transformer service is straight-forward. At first, it retrieves the JSON files that Harvester has stored in MinIO. It merges them into one JSON file and removes the base path from the source path. Then, it flattens the data so we can use it as an input for Pandas. The transformations that the user has defined in the UI are applied (by using Pandas). Then, the transformed file is being stored to MinIO (/transform path). The transformation stats are calculated and are sent along with the feedback message with RabbitMQ. If a transformation fails, the step fails and the failure details are sent instead.
Configuration File
A JSON configuration file is required from the Transformer. The requirements of the configuration file are described in the transformer_schema.py file that exists in the Transformer Project.
Available Transformations
Available transformations are described in the transformations.py file that exists in the Transformer Service.